[운영체제] Processec-IPC
[운영체제] Processec-IPC
Interprocess Communication
프로세스는 시스템 내에서 독립적이거나 협조적일 수 있다.
프로세스가 협동을 하는 이유
- 정보 공유
- 계산 속도 향상
- 분업(각각의 모듈이 독립적으로 실행해서 일을 분담)
- 편리
협조적인 프로세스는 프로세스 간 통신(IPC, interprocess communication)이 필요하다.
IPC의 두 가지 모델
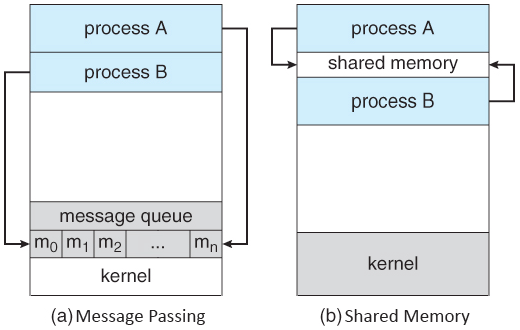
| Message Passing | Shared Memory | |
|---|---|---|
| Implementation(구현) | 쉽다, Easy | 어렵다, Difficult |
| Speed(속도) | 느리다, Slow | 빠르다, Fast |
| Kernel intervention(커널 간섭 혹은 관여) | 많이, alot, via system calls | 조금, 적다(없다 = X), No system calls except setup |
| Data size(데이터 크기) | 작은용량, Good for small amount | 대용량, Good for large amount |
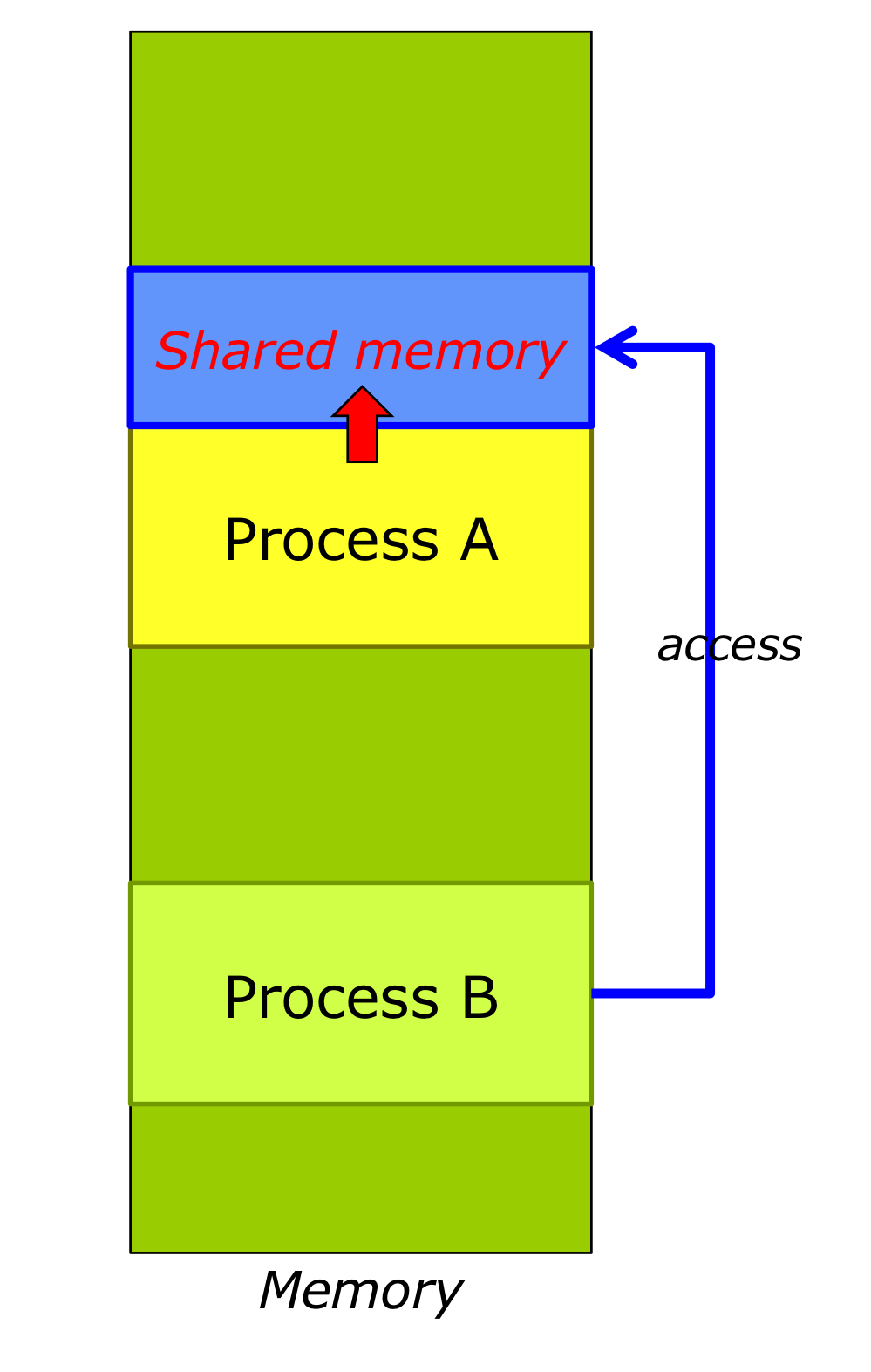
Shared Memory Systems
1
2
3
4
5
6
7
8
9
10
11
12
13
14
+--------------------+ +--------------------+
| Process A | | Process B |
| (Producer/Writer) | | (Consumer/Reader) |
| | | |
| Local Variables | | Local Variables |
| Code & Stack | | Code & Stack |
+--------------------+ +--------------------+
\ /
\ /
\ Shared Memory /
+-------------------+
| Shared Buffer |
| or Data Area |
+-------------------+
- Process A의 Adress Space인 동시에 Process B의 Adress Space.
- 자신 Process의 Adress Space에 타인 Process가 접근 못한다는 것의 반례
프로세스 A가 공유 메모리(Shared Memory)를 만든다.
- 공유 메모리 안에 프로세스 A의 주소 공간(Adress Space)이 존재한다. 공유 메모리에 프로세스 B가 접근할 수 있도록 허락한다. 미리 정의된 데이터 형식은 없다.
Producer-Consumer Model
Producer-Consumer Model(생성자 - 소비자 모델)
- Procuer(생산자)는 데이터를 만든다. -> 데이터를 쓰고(wirtes information)
Consumer(소비자)는 데이터를 소비한다. -> 그것을 가져가 사용한다(reads information)
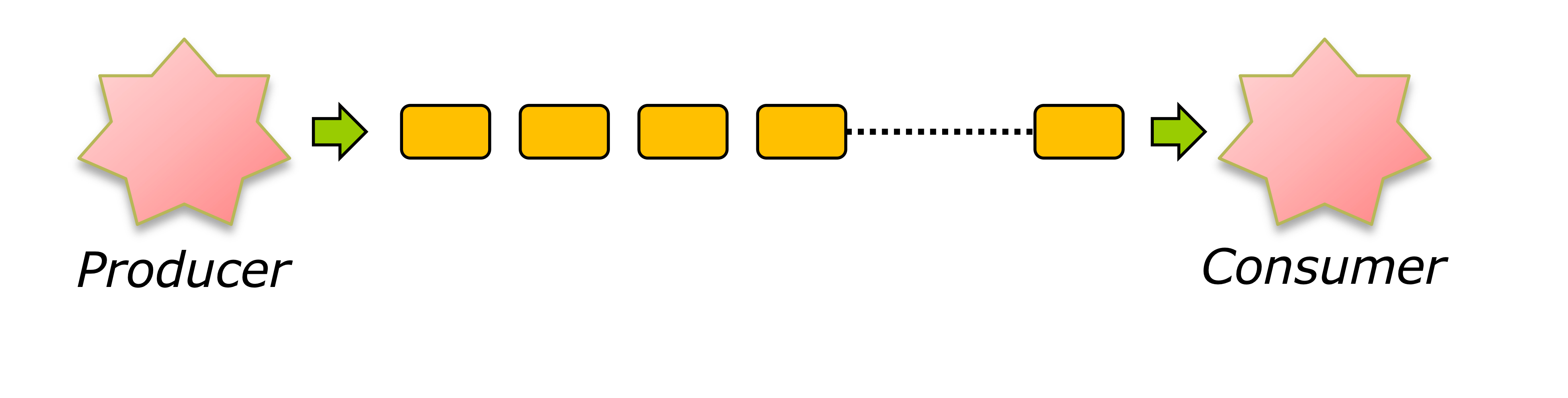
- 버퍼(buffer)를 이용해 생산자가 소비자에게 택배기사처럼 정보를 배달한다.(순서를 유지하면서)
- 생산자와 소비자 사이에 버퍼가 중간에서 데이터를 저장/전달하는 역할을 한다.(위 사진 참조)
Shared Buffer Model
Unbounded Buffer -> 현실적이 않다.
- 버퍼 크키가 무한하다고 가정한다.
- 생산자는 언제든 데이터 추가(생성)가 가능하다.
- 만약에 버퍼가 비었다면, 소비자가 데이터를 읽지(소비하지) 못한다.
Bouded Buffer
- 버퍼 사이즈의 제한이 있다. -> 끝이 존재한다.
- 만약 버퍼가 꽉찼다면, 생산자는 데이터를 생산하면 안된다. -> 버퍼가 언제 full인지 알아야 한다.
- 만약 버퍼가 비었다면, 소비자는 데이터를 소비하면 안된다. -> 버퍼가 언제 비었는지 고민해야 한다.
문제점
- 생산자가 데이터를 너무 빨리 만들면 -> 버퍼가 가득 찬다.
- 소비자가 너무 빨리 가져가면 -> 버퍼가 비어 있다.
해결책
- in과 out이 같아지는 순간이 버퍼가 비는 순간이다.
- 생산자는 버퍼에 공간이 비었을 때만 데이터를 넣는다.
- 소비자는 버퍼에 데이터가 있을 때만 데이터를 꺼내간다.
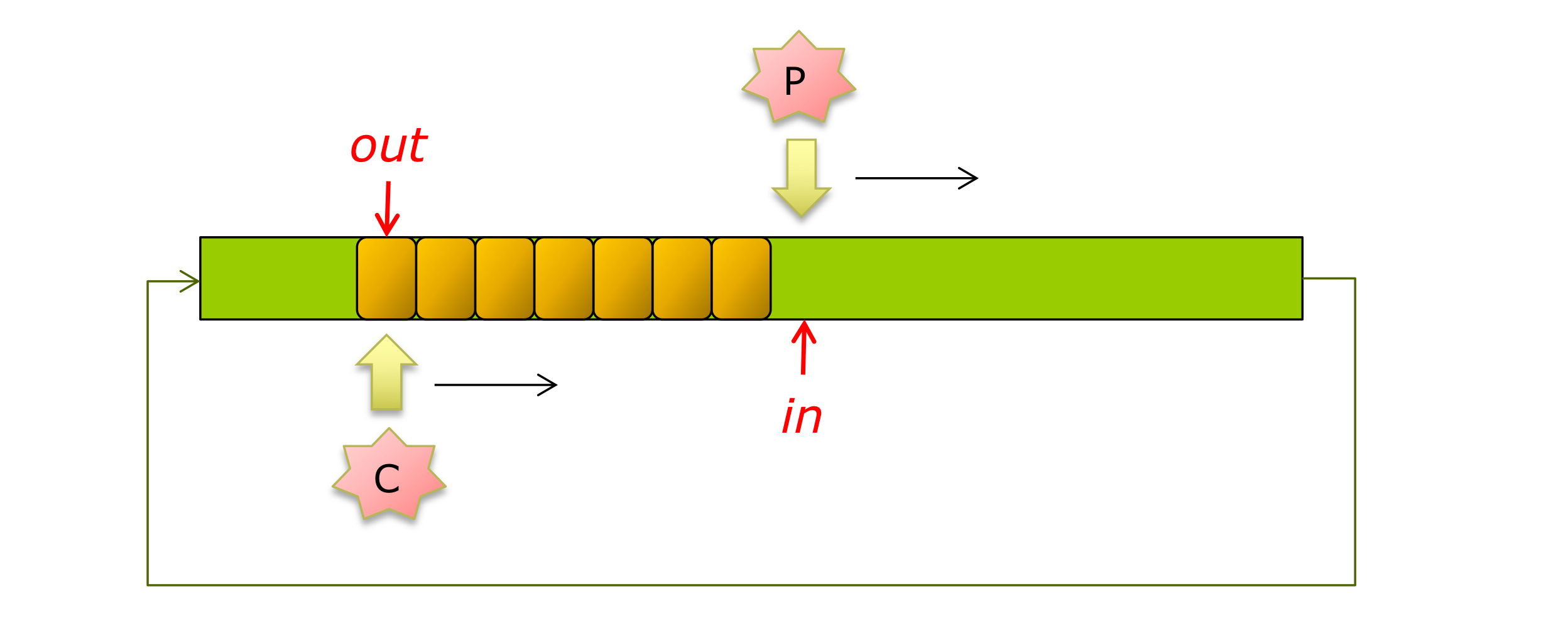
Shared Buffer by Circular Array
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
define BUFF_SIZE 100
typedef struct {...} item;
item buffer[BUFF_SIZE]
//in: index to write new data
int in = 0;
//out: index to read new data
int out = 0;
*Buffer is empty if
out == in
*Buffer is full if
(in+1) % BUFF_SIZE == out
*Maximum items count
BUFF_SIZE -1
*Can we use all buffer?
- 일반 배열은 버퍼가 가득 차거나 비면 처음부터 다시 사용하기 어렵다.
- 반면 원형 배열은 끝까지 가면 다시 처음으로 돌아갈 수 있어서 메모리를 효율적으로 사용한다.
- 한정된 크기의 배열을 반복해서 쓸 수 있게 해주는 구조다.
Ordinary Pipes
부모 자식간 통신할 때 사용된다. 끝과 끝이 존재하고 생성자가 한쪽 끝에서 읽고, 다른 한쪽 끝에서 소비자가 사용한다. ordinary pipe는 단 방향이다.
Named Pipes
프로세스가 죽으면 다 날아간다. named pipe는 ordinary pipe보다 더 강력하다.
- 양방향 소통이 가능하다.
- 부모 자식 관계가 필요 없다.
- 다수의 프로세스들이 사용가능하다. ex) mail box같이 여러가지 프로세스가 접근할 수 있다.
- 유닉스와 윈도우에 다 있는 기능이다.
유닉스
먼저 읽은게 먼저 나간다. 파일 시스템에서 마지막으로 지워줄때까지 존재한다. 양방향으로 통신가능하지만 반이중이다. 한쪽에서 송신 중이면 다른쪽에서 수신불가, 반대로 한쪽에서 수신중이면 다른쪽에서 송신 불가하다.
윈도우
양방향으로 통신가능하고 전이중이다. 동시에 써도 가능하다. 양방향 송수신
유닉스 도메인 소켓
유닉스 도메인 안에서 통신할 때 사용한다. 퍼포먼스는 ordinary pipe > unix domain socket > named pipe > network socket 순이다.
- 아직 수정 중
이 기사는 저작권자의 CC BY 4.0 라이센스를 따릅니다.